Important advantage, frequently underestimated,
offers from data capture is a possibility of
make a simultaneasly elaboration of different type documents
leaving at software the incumbency of recognizing the nature
order to treat them each according to their specific.
It is a real process of automatic classification,
or assignment of document to a document class (for example:
invoice, order, contract, claim, solicitous, etc.)
that can applied at structured modules and unstructured documents.
When is possible, can be using a technique of (form identification), or
module identification, that having a fixed structured and invariable, can be recognized verifying
the presence of constat graphic elements for example linees, brands, box and columns.
Usually use this technique required the steps of "training"
in which the system is subjected samples of forms to be recognized so that it can extract
the graphic features and create a sort of database to be used for subsequent identification of unknown instances.
When this is not the modules will use a technique keywording,
or identification of significant keywords, subject to OCR the entire page,
which constitute a lowest common denominator for each type of document to be processed.
The identification of these keywords can be done manually or automatically.
In the first case is left to the sensibility and experience of an operator to identify
which are the keywords to be used for each document class.
In the second case instead these keywords are identified
automatically by the system by sending it a sufficient
number of documents for each of the type including distinguish.
It important to note that this technology can also be used when processing a single type of document, but a multi page,
to verify the exact order of the side that make it up to be sure that there were no scanning errors that may lead to unimaginable consequences in the event
of a jump or exchange page.
Not to be underestimated is also one of the "sub products" that can result in a natural way from the classification of documents, or the ability to obtain the correct orientation, correcting any scans upside down.
To clarify the application fiedl of this technology, we report any example of a real application developed for the service of
customer care of an important italian telephonic operator.
The needs of depature was to be to make that each received document could be given the right destination for this "work"
and a priority based on the specific typology.
Indeed, merging the customer request into a single digital stream, both with a fax server and with massive scanning
of paper received into mailboxe, it wa not possible to attribute a priority and
routing irrespective,
less than that of human operators not evaluate manually the content of each of them.
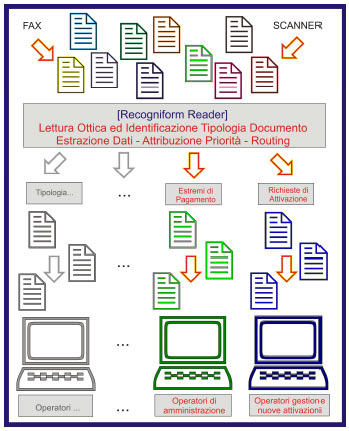
Using our data capture platform, Recogniform Reader, it was possible to make that this documents where classified automatically, either by
form identification and keywording, so as to attribute immediately priority e routing to each of them.
Example of architecture for the identification and sorting documents automatically implemented Recogniform Reader at the customer care of an important telephone operator.
The initial scenario was thus to have a queue of thousands of documents to be processed daily,
the activity could only play only sequentially, with the operator who manually looked at the video the invidual documents to decide who forward and if
work it immediately or not, according to the directives received.
The ending scenario is has become rather one in which each operator of customer care received the documents that already have to work in order
of priority and even with some of the data already "extract" ready to be insert into CRM/Management busigness!
One huge advantage then that concretized into a saving time and resource and a improvement of quality of service offered to customer.